![]()
This website presents research results of the Artificial Intelligence and Machine Learning [AI:ML] lab at the University of St. Gallen.
Our deep neural networks research focuses on representation learning through supervised and unsupervised approaches with applications to text-to-speech generation, computer vision and remote sensing, and financial time-series data.
Below you can find some recent results from the AIML lab:
-
Sparse Multimodal Vision Transformer for Weakly Supervised Semantic Segmentation
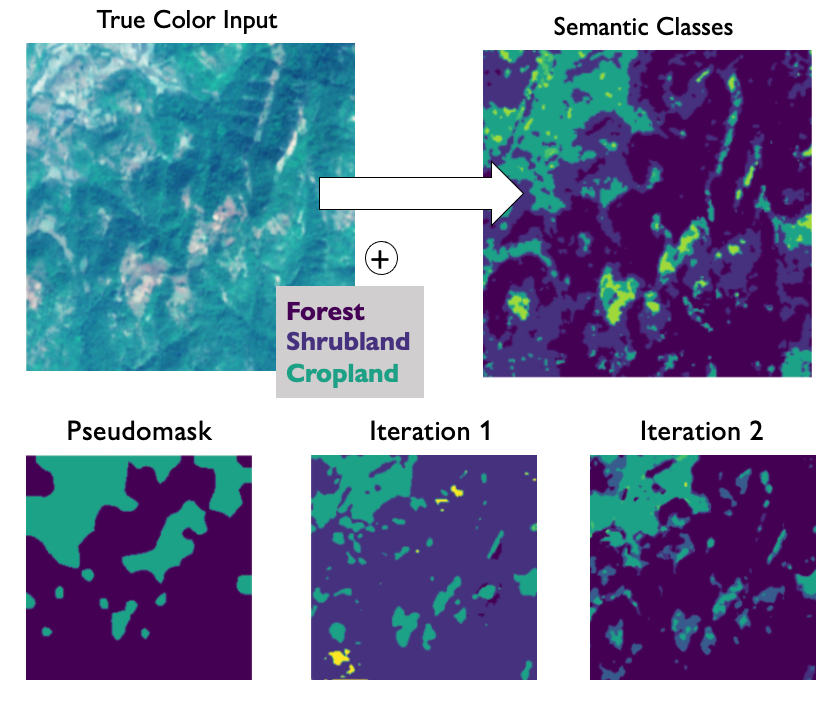
Our primary objective is to perform semantic segmentation without relying on pixel-level annotations. Instead, we use image-level annotations, making the segmentation task more scalable and cost-effective. To accomplish this, we investigate attention modules in a Vision Transformer. These modules provide greater interpretability compared to CNN-based approaches and enable us to generate pseudo-segmentation masks. These masks are subsequently refined iteratively, leading to improved segmentation results. Vision Transformers have demonstrated their versatility and effectiveness in tackling complex computer vision tasks such as land cover segmentation in remote sensing applications. While they perform comparably or even better than Convolutional Neural Networks (CNNs), Transformers typically require larger datasets with detailed annotations, such as pixel-level labels for land cover segmentation. To address this limitation, we propose a weakly-supervised vision Transformer that utilizes image-level labels to learn semantic segmentation and reduce the need for extensive human annotation. This is achieved by modifying the architecture of the vision Transformer, incorporating gating units in each attention head to enforce sparsity during training and retain only the most meaningful heads. After training on image-level labels, we extract the representations from the remaining heads, cluster them, and construct pseudomasks serving as labels for training a segmentation model. Furthermore, we can refine our predictions through post-processing the pseudomasks and iteratively training a segmentation model with high fidelity. Our code is available at github.com/HSG-AIML/sparse-vit-wsss. Evaluation on the DFC2020 dataset demonstrates that our method not only produces high-quality segmentation masks using image-level labels but also performs comparably to fully-supervised training relying on pixel-level labels. Our results also indicate that our method can accomplish weakly-supervised semantic segmentation even with small-scale datasets.
-
Masked Vision Transformers for Hyperspectral Image Classification
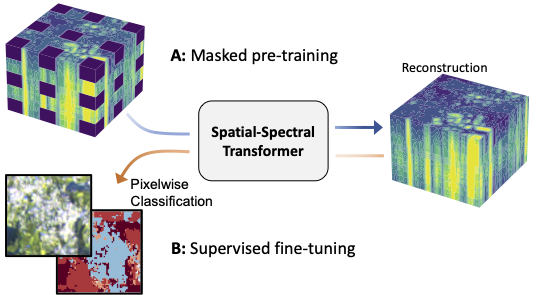
A: We propose the use of masked image modeling to pre-train spatial-spectral transformer networks on a large dataset of unlabeled hyperspectral EnMAP data. B: The pre-trained model can then be fine-tuned on small labeled datasets for supervised downstream tasks like land cover classification. Transformer architectures have become state-of-the-art models in computer vision and natural language processing. To a significant degree, their success can be attributed to self-supervised pre-training on large scale unlabeled datasets. This work investigates the use of self-supervised masked image reconstruction to advance transformer models for hyperspectral remote sensing imagery. To facilitate self-supervised pre-training, we build a large dataset of unlabeled hyperspectral observations from the EnMAP satellite and systematically investigate modifications of the vision transformer architecture to optimally leverage the characteristics of hyperspectral data. We find significant improvements in accuracy on different land cover classification tasks over both standard vision and sequence transformers using (i) blockwise patch embeddings, (ii) spatial-spectral self-attention, (iii) spectral positional embeddings and (iv) masked self-supervised pre-training (Code available at github.com/HSG-AIML/MaskedSST). The resulting model outperforms standard transformer architectures by +5% accuracy on a labeled subset of our EnMAP data and by +15% on Houston2018 hyperspectral dataset, making it competitive with a strong 3D convolutional neural network baseline. In an ablation study on label-efficiency based on the Houston2018 dataset, self-supervised pre-training significantly improves transformer accuracy when little labeled training data is available. The self-supervised model outperforms randomly initialized transformers and the 3D convolutional neural network by +7-8% when only 0.1-10% of the training labels are available.
-
Fine-grained Emotional Control of Text-To-Speech Learning To Rank Inter- And Intra-Class Emotion Intensities
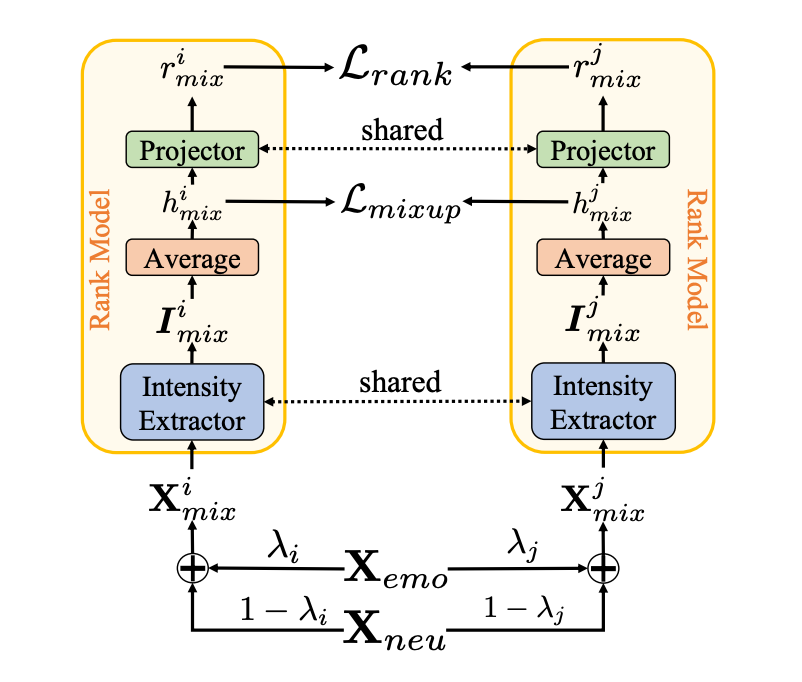
The pipeline of our Intensity Extractor model. The inputs are a pair of mixture speech samples. Each of these samples is a mix of the same non-neutral and neutral speech, but with different weights applied. The object is to accurately rank these two mixtures. If the ranking is done correctly, it indicates that the extracted intensity representation is meaningful. -
NeurIPS 2022 - Model Zoo Datasets and Generative Hyper-Representations
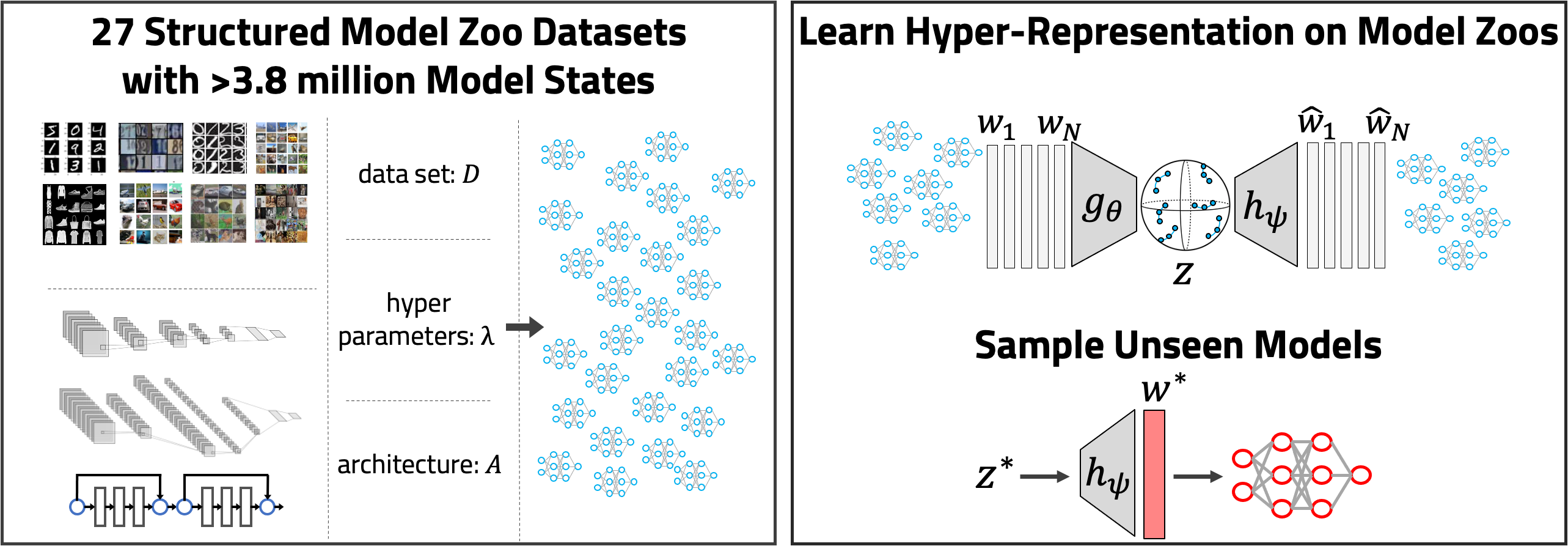
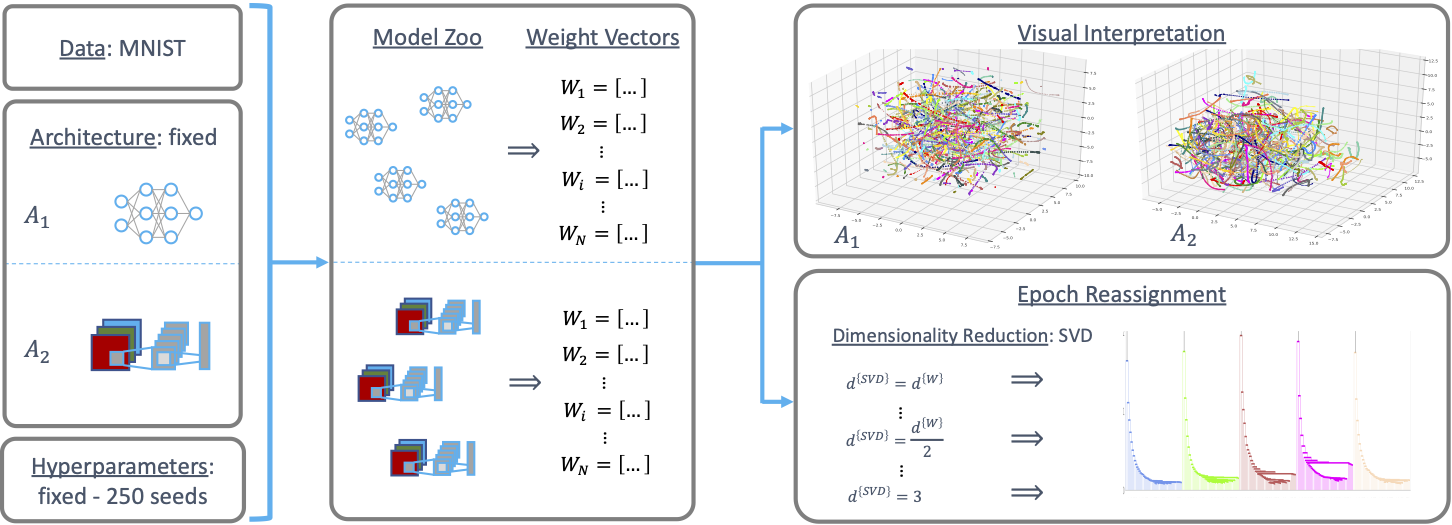
At this year's Neurips, we present Model Zoo Datasets and Generative Hyper-Representations. Introduction
Learning on populations of Neural Networks (NNs) has become an emerging topic in recent years. The high dimensionality, non-linearity and non-convexity of NN training opens up exciting research questions investigating populations: i) do individual models in populations have something in common? ii) do models form meaningful structures in weight space? iii) can representations be learned of such structures? iv) can such structures be exploited to generate new models?
At last year’s NeurIPS, we took first steps to find answers to these questions with our paper presenting hyper-representations. There, we showed that populations of models, called model zoos, are indeed structured. With hyper-representations, we proposed a self-supervised learning method to learn representations of the weights of model zoos. Further, we showed that these representations are meaningful in the sense that they are predictive of model properties, such as their accuracy, epoch or hyperparamters.
At this year’s NeurIPS, two more contributions in this research direction got accepted: 1) the Model Zoo Dataset to facilitate research in that domain; and 2) Generative Hyper Representations to sample new NN weights. -
Self-supervised Vision Transformers for Land-cover Segmentation and Classification
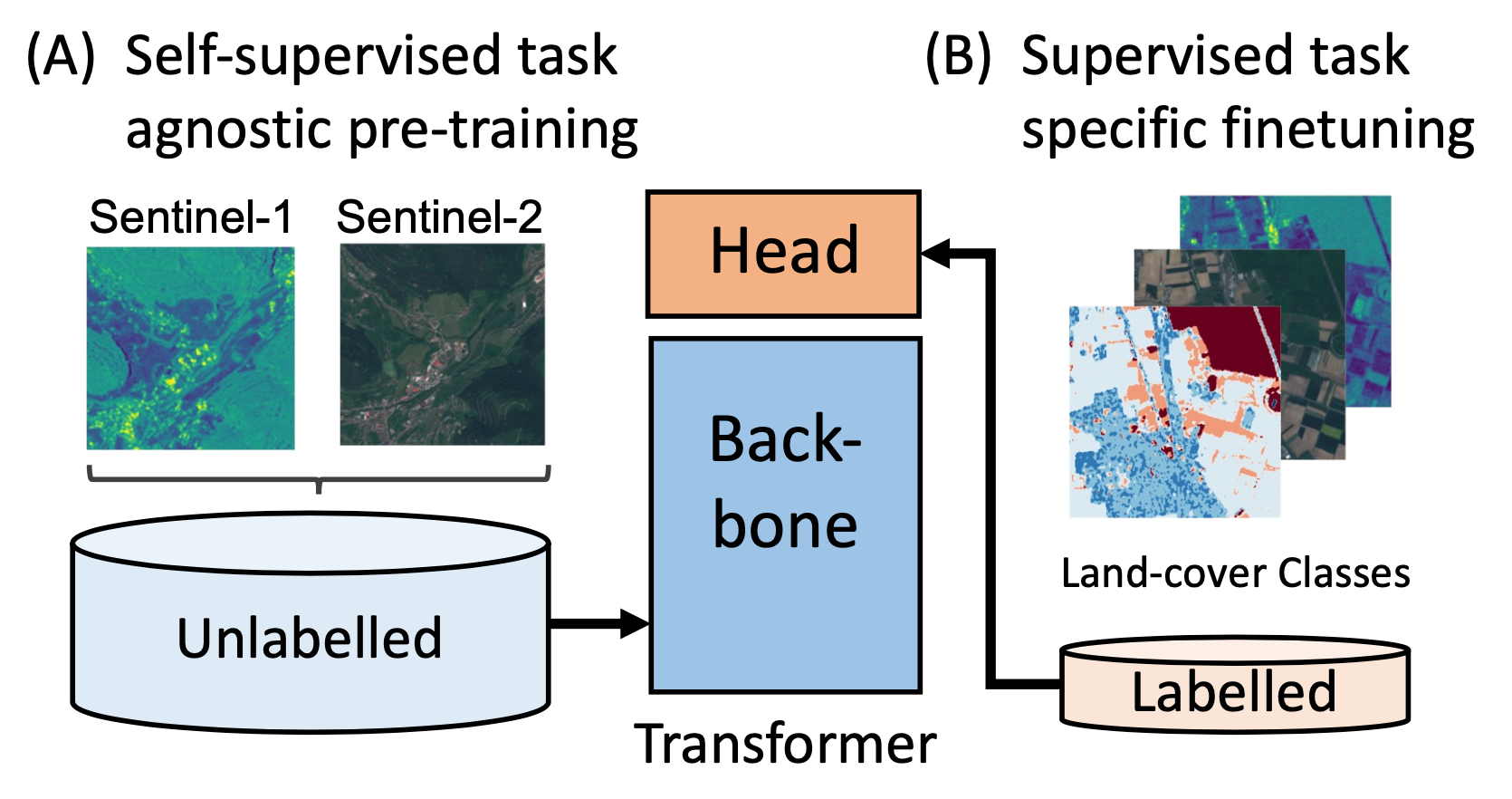
An overview of our self-supervised multi-modal contrastive learning approach for Vision Transformers. We propose to use large datasets of unlabelled multi-modal remote sensing data (Sentinel-1 and Sentinel-2) for self-supervised pre-training of vision Transformers using a contrastive loss. After self-supervised training of the backbone (A), the model and task-specific head can be fine-tuned on much smaller labelled datasets for different downstream tasks (B), such as land-cover segmentation and classification. Transformer models have recently approached or even surpassed the performance of ConvNets on computer vision tasks like classification and segmentation. To a large degree, these successes have been enabled by the use of large-scale labelled image datasets for supervised pre-training. This poses a significant challenge for the adaption of vision Transformers to domains where datasets with millions of labelled samples are not available. In this work, we bridge the gap between ConvNets and Transformers for Earth observation by self-supervised pre-training on large-scale unlabelled remote sensing data. We show that self-supervised pre-training yields latent task-agnostic representations that can be utilized for both land cover classification and segmentation tasks, where they significantly outperform the fully supervised baselines. Additionally, we find that subsequent fine-tuning of Transformers for specific downstream tasks performs on-par with commonly used ConvNet architectures. An ablation study further illustrates that the labelled dataset size can be reduced to one-tenth after self-supervised pre-training while still maintaining the performance of the fully supervised approach.
-
Contrastive Self-Supervised Data Fusion for Satellite Imagery
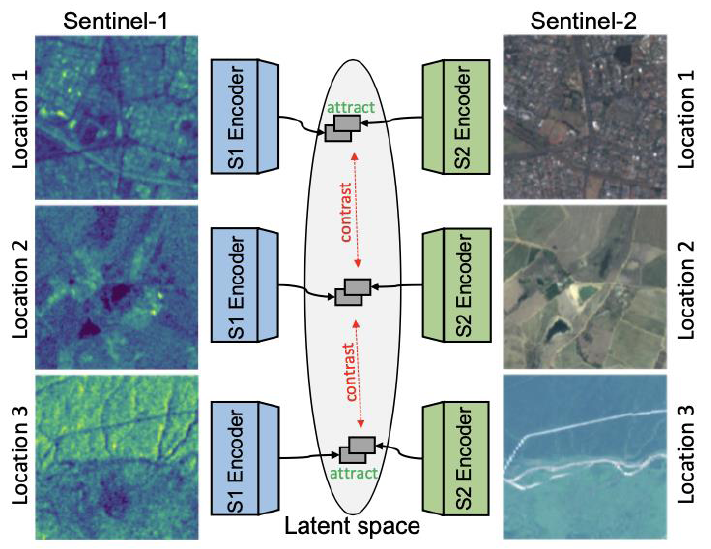
A schematic depiction of our multi-modal contrastive self-supervised learning approach: by leveraging a contrastive loss, we force latent representations generated from multi-band imaging (Sentinel-2) and SAR data (Sentinel-1) for the same location to attract in latent space, while forcing representations generated for different locations to repel each other. As a result, the model learns rich representations that can be fine-tuned for any downstream task. Supervised learning of any task requires large amounts of labeled data. Especially in the case of satellite imagery, unlabeled data is ubiquitous, while the labeling process is often cumbersome and expensive. Therefore, it is highly worthwhile to leverage methods to minimize the amount of labeled data that is required to obtain a good performance of the given down-stream task. In this work, we leverage contrastive learning in a multi-modal setup to achieve this result.
-
Commercial Vehicle Traffic Detection from Satellite Imagery with Deep Learning

Green boxes indicate commercial vehicles (CV) as they move on a Swiss freeway section. Due to a delay in the imaging of the different channels, moving objects exhibit a characteristic rainbow-like appearance in Sentinel-2 images. This project exploits this characteristic feature to identify and measure commercial vehicle traffic from space. Commercial vehicle traffic is currently responsible for 7% of global CO2 emissions. While road freight will remain the dominant mode of surface freight transportation, its contribution to climate change is likely to increase in the short term. Therefore, the quantitative monitoring of commercial vehicle (CV) traffic is essential for implementing targeted road emission regulations. However, ground monitoring stations are costly and less than half of all countries worldwide collect road freight activity. In this work, we investigate the feasibility of detecting and monitoring CV traffic in freely available satellite imagery from ESA’s Sentinel-2 satellites.
-
Self-Supervised Representation Learning on Neural Network Weights for Model Characteristic Prediction
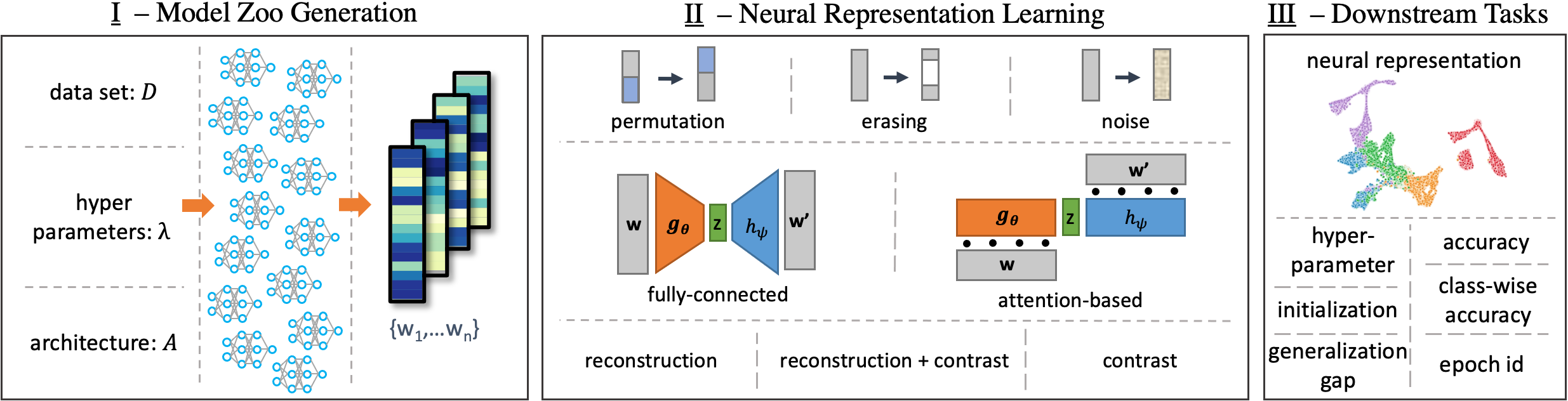
An overview of the proposed self-supervised representation learning approach. I. Populations of trained NNs form model zoos; each model is transformed in a vectorized form of its weights. II. Neural representations are learned from the model zoos using different augmentations, architectures, and Self-Supervised Learning tasks. III. Neural representations are evaluated on downstream tasks which predict model characteristics. Self-Supervised Learning (SSL) has been shown to learn useful and information-preserving representations. Neural Networks (NNs) are widely applied, yet their weight space is still not fully understood. Therefore, we propose to use SSL to learn neural representations of the weights of populations of NNs. To that end, we introduce domain specific data augmentations and an adapted attention architecture. Our empirical evaluation demonstrates that self-supervised representation learning in this domain is able to recover diverse NN model characteristics. Further, we show that the proposed learned representations outperform prior work for predicting hyper-parameters, test accuracy, and generalization gap as well as transfer to out-of-distribution settings.
-
Self-Supervised Learning of Accounting Data Representations for Downstream Audit Tasks
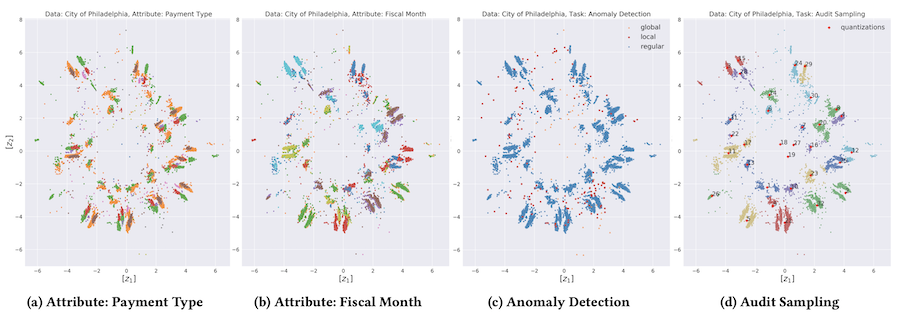
Learned task invariant accounting data representations zi in R2 with τ = 0.5 of the 238,894 City of Philadelphia vendor payments. The visualisations on the left show the representations coloured according to selected payment characteristics: payment type (a) and posting month (b). The visualisations on the right show the same representations coloured according to the downstream audit task: anomaly detection (c) and audit sampling (d). International audit standards require the direct assessment of a financial statement’s underlying accounting transactions, referred to as journal entries. Recently, driven by the advances in artificial intelligence, deep learning inspired audit techniques have emerged in the field of auditing vast quantities of journal entry data. Nowadays, the majority of such methods rely on a set of specialized models, each trained for a particular audit task. In this work we propose a contrastive self-supervised learning framework designed to learn audit task invariant accounting data representations. The framework encompasses deliberate interacting data augmentation policies that utilize the attribute characteristics of journal entry data. We evaluate the framework on two real-world datasets of city payments and transfer the learned representations to three downstream audit tasks: anomaly detection, audit sampling, and audit documentation. Our experimental results provide empirical evidence that the proposed framework offers the ability to increase the efficiency of audits by learning rich and interpretable multi-task representations.
-
Estimation of Air Pollution with Remote Sensing Data: Revealing Greenhouse Gas Emissions from Space
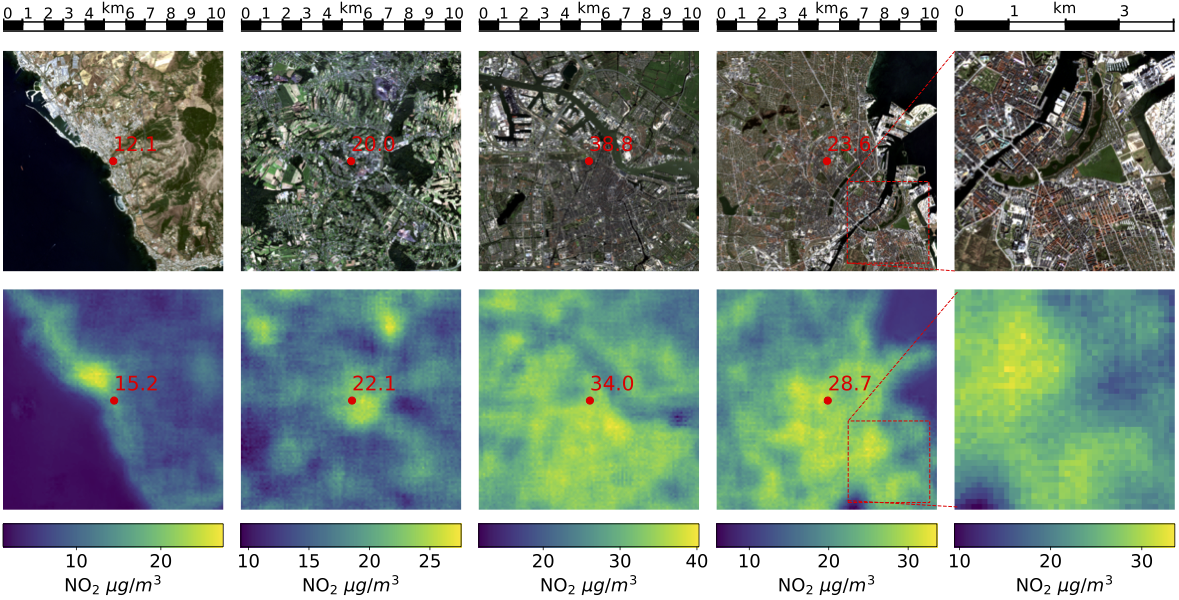
Exemplary NO2 predictions based on Sentinel-2 and Sentinel-5P input data. **Top:** RGB bands of the Sentinel-2 image, red dots mark locations of air quality stations, red text indicates the average NO2 concentration measured on the ground during the 2018-2020 timespan. **Bottom:** Predicted NO2 concentrations for the locations above (not seen during training) with predictions at the exact position of the air quality station in red. The heatmaps are constructed from individual predictions for overlapping 120x120 pixel tiles of the top image and corresponding Sentinel-5P data, resulting in an effective spatial resolution of 100m. This approach is equally applicable to locations without air quality stations, providing a means to map air pollution on the surface level to identify sources of air pollution and GHG emissions. Air pllution is a major driver of climate change. Anthropogenic emissions from the burning of fossil fuels for transportation and power generation emit large amounts of problematic air pollutants, including Greenhouse Gases (GHGs). Despite the importance of limiting GHG emissions to mitigate climate change, detailed information about the spatial and temporal distribution of GHG and other air pollutants is difficult to obtain. Existing models for surface-level air pollution rely on extensive land-use datasets which are often locally restricted and temporally static. This work proposes a deep learning approach for the prediction of ambient air pollution that only relies on remote sensing data that is globally available and frequently updated. Combining optical satellite imagery with satellite-based atmospheric column density air pollution measurements enables the scaling of air pollution estimates (in this case NO2) to high spatial resolution (up to ~10m) at arbitrary locations and adds a temporal component to these estimates. The proposed model performs with high accuracy when evaluated against air quality measurements from ground stations (mean absolute error <6 microgram/qm). Our results enable the identification and temporal monitoring of major sources of air pollution and GHGs.
-
Visualization of Earth Observation Data with the Google Earth Engine
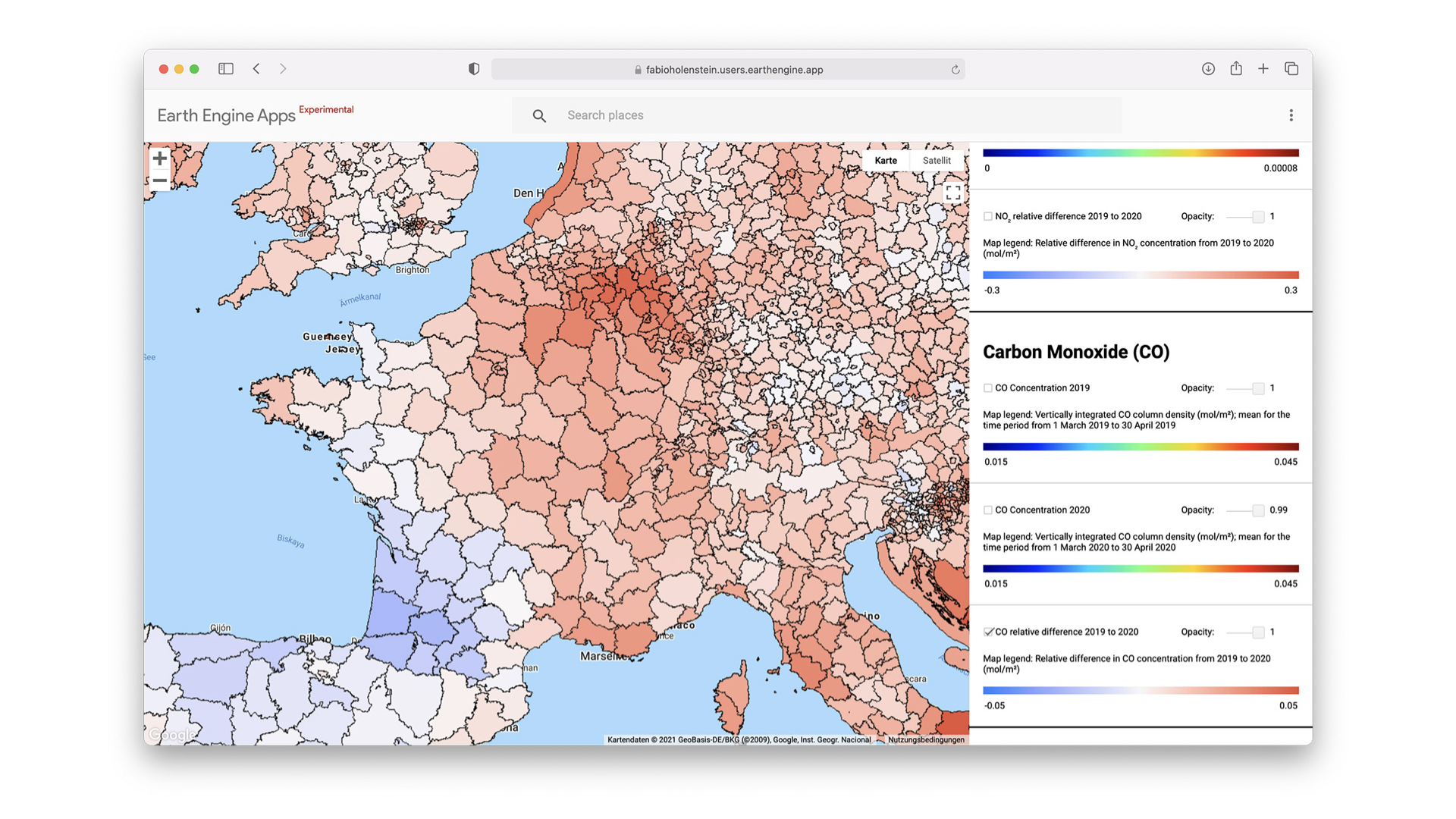
Example visualization of CO in central Europe. Earth observation provides the basis for a better understanding of our planet. The amount of data available for the creation of this understanding has steadily increased as a result of technological progress and the growth in the frequency of measurements. In research, this leads to the challenge that conducting holistic analyses and extracting relevant information from large Earth observation datasets requires significant development effort and specific expertise in cloud computing services. Therefore, user-friendly solutions are needed that combine data storage, processing and analysis. With the Earth Engine, a cloud-based platform for geospatial data analysis, Google provides a promising platform in this regard. This work evaluates the suitability of the Google Earth Engine for use in research to perform analyses of large Earth observation datasets as well as to create meaningful and easy-to-use interactive visual representations.
-
Power Plant Classification from Remote Imaging with Deep Learning

Example images and class activation maps for two coal power plants from our sample that were correctly identified. The heatmap plots highlight areas on which the trained model bases its class prediction. In this case, the model focuses on the presence of coal heaps that are indeed indicative of coal-powered plants. The industrial and power-generating economic sectors emit more than half of the annually and globally released greenhouse gas emissions, strongly contributing to global warming effects. In our recent work (Mommert et al. 2020) we laid the foundation to estimating greenhouse gas emissions from industrial sites by characterizing industrial smoke plumes from remote imaging data only. That work is part of a bigger effort to estimate greenhouse gas emission rates from satellite imagery for individual industrial sites. In this work, we made one further step towards achieving this goal.
-
A Novel Dataset for the Prediction of Surface NO2 Concentrations from Remote Sensing Data
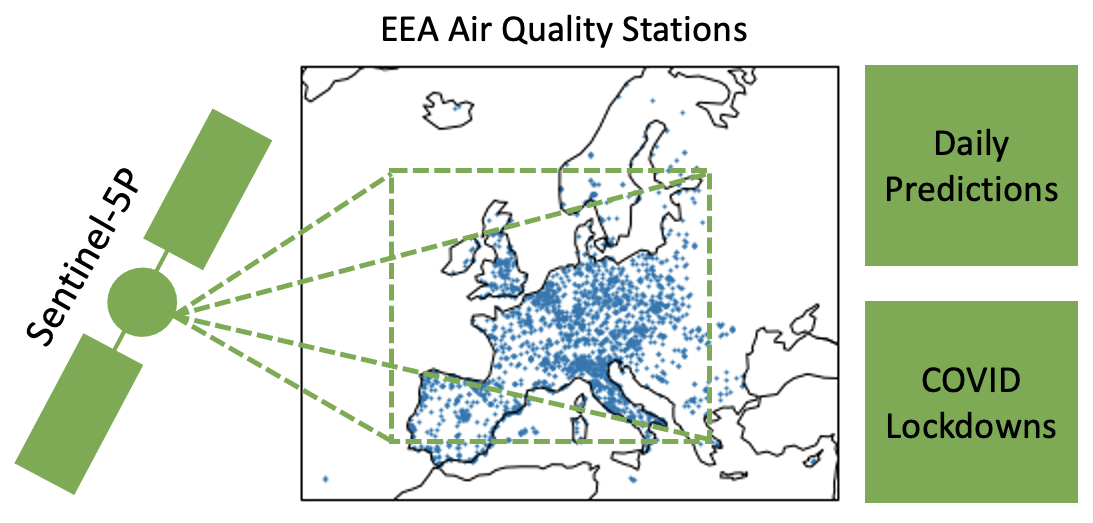
The NO2 dataset consists of spatially and temporally aligned measurements from the ESA Sentinel-5P satellite, EEA air quality stations on the ground and supplementray data. NO2 is an atmospheric trace gas that contributes to global warming as a precursor of greenhouse gases and has adverse effects on human health. This work present a novel dataset of NO2 measurements from air quality stations on the ground, temporally and spatially aligned with NO2 measurements from space by the ESA Sentinel-5P satellite. Additionally, geographic and meteorological variables as well as information on lockdown measures are included. The dataset offers access to diverse data on NO2, and facilitates data-driven research into the dynamics of NO2 pollution.
-
An Investigation of the Weight Space of Neural Networks for Monitoring of the Training Progress and Version Control
The parameters of Neural Networks (NNs) develop on smooth, unique trajectories during training. Using clustering methods in parameter space, these trajectories can be recovered without labels, and even the order of checkpoints on the trajectories restored to some degree. We hypothesise that the shape of the trajectories contains information on the training progress, and may reveal domain shifts in the training data or adversarial attacks. Therefore, training trajectories may be used for monitoring of the training progress, and supply useful information for NN model versioning.
-
Leaking Sensitive Financial Accounting Data in Plain Sight using Deep Autoencoder Neural Networks
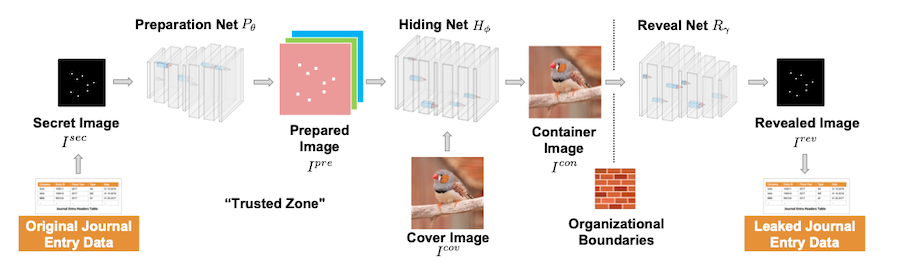
The data leakage process applied to learn a steganographic model of real-world accounting data. The process is designed to encode and decode sensitive Enterprise Resource Planing (ERP) system information into unobtrusive ‘day-to-day’ cover images. Nowadays, organizations collect vast quantities of sensitive information in ‘Enterprise Resource Planning’ (ERP) systems, such as accounting relevant transactions, customer master data, or strategic sales price information. The leakage of such information poses a severe threat for companies as the number of incidents and the reputational damage to those experiencing them continue to increase. At the same time, discoveries in deep learning research revealed that machine learning models could be maliciously misused to create new attack vectors.
-
Characterization of Industrial Smoke Plumes from Remote Sensing Data

Example images from our set of 21,350 images of industrial sites. Each column corresponds to one of 624 emitter locations. The top row shows the site during activity (smoke is present) and the bottom row during inactivity (smoke is absent). The origin region of the smoke plume is marked by red circles. The major driver of global warming has been identified as the anthropogenic release of greenhouse gas (GHG) emissions from industrial activities. The quantitative monitoring of these emissions is mandatory to fully understand their effect on the Earth’s climate and to enforce emission regulations on a large scale. In this work, we investigate the possibility to detect and quantify industrial smoke plumes from globally and freely available multi-band image data from ESA’s Sentinel-2 satellites.
-
Künstliche Intelligenz in der Prüfungspraxis – Eine Bestandsaufnahme aktueller Einsatzmöglichkeiten und Herausforderungen
Während künstliche Intelligenz die Arbeitsweise verschiedener Berufsgruppen zunehmend und nachhaltig verändert, steckt ein solcher Wandel im Bereich der Wirtschaftsprüfung derzeit in seinen Anfängen. Der nachfolgende Beitrag soll Einsatzmöglichkeiten und Herausforderungen des maschinellen Lernens (ML), eines Teilgebiets der künstlichen Intelligenz, im Kontext der Abschlussprüfung aufzeigen.